I think if there is enough interest in this setting up a patreon page or something similar would make a lot of sense. Also there is a a b-stock dwarf at thomann for 365€ - maybe this is an option to for a few people to chip in.
7 Likes
It’s sounding great!
3 Likes
ne need to be afraid. The dwarf uses linux at its core so its pretty unbrickable. Worst case is you reset the device and load your backups.
Always keep a backup (2 seperate drives) of your backups and the firmware.
5 Likes
Thought I’d share here for anyone interested, I have a new plugin out called EpochAmp, here’s a video, and you can download it for free from GuitarML.com. I had almost as much fun making the video as I did making the plugin. Enjoy!

12 Likes
I just fired it up in Ableton out of curiosity and… it’s pretty good. Granted I didn’t do extensive testing or ABing, I just strummed a few chords, realized that mode two effortlessly gives me that ‘edge of breakup’ thing that I like, slapped an Ownhamer IR on it and was like “sure, I could record with this”.
Few points of feedback:
A mix knob - while potentially useful in general music production - is less useful from a strict guitar playing perspective (unless maybe someone wanted to run an acoustic trough it, but there are other ways to mix a plugin into your signal inside a DAW). A basic tone knob (even if that would have to be a post-amp eq given that this is a captured/profiled/emulated amp) would be infinitely more useful. My main guitar was a touch too dark with this amp, and I quickly remedied that with another plugin but a tone knob would be ideal.
Some basic documentation/description of what each mode resembles/emulates would be helpful. I’m sure there’s a philosophical discussion here about expectations affecting the way we perceive tone, but I think most guitar players find basic generalizations (“American black panel amp”, “plexi”, “vox-style” w/e) useful. That second mode sounded kinda-sorta like a Marshall or maybe non top boosted Vox. but I don’t really know.
CPU usage is not outrageous by any means, but it’s in the neighbourhood of something like Helix Native/Amplitube/Guitar Rig, which for a single amp is on a higher said. Though I guess amps based on machine learning are inherently more resource heavy than modelling (just guessing based on experience with other plugins).
This is just a preference so you can completely disregard it but I don’t care for skeuomorphic look.
In general, great stuff. This is the kind of Amp Dwarf needed more of - easy to use but great sounding.
6 Likes
 I have also released a new version (0.93) of my plugin together with completely re-trained models and I need some feedback. You can use it on Desktop but only if you support lv2. I still need to relase binaries, working on it. I will summarize here the features of my plugin:
I have also released a new version (0.93) of my plugin together with completely re-trained models and I need some feedback. You can use it on Desktop but only if you support lv2. I still need to relase binaries, working on it. I will summarize here the features of my plugin:
- built to be a generic neural model player
- support for three network types (ideal for: pedals, middle complex amp tone, highly complex amp)
- complexity means network depth means cpu consumption
- two conditioning params available for each network types (param1 and param2)
- model file is standardized to be rt neural library compatible, plus
- skip parameter, which tells you if the training has been made by propagating the input to the output (a sort of dry/wet mix)
- this parameter together with network type depends on the model you’re going to emulate and you can’t know in advance if it will improve the overall result or not
- I’ve studied the available papers that conclude that A-Weighting is the best pre-emphasis function among the ones available / used until now. While I’m experimenting on this topic (@keyth72 we can setup a thread on this?) by ear I can say that the models trained in this way sounds better
- the plugin has a volume input and master output, plus a low pass filter with variable frequency at the input to deal with aliasing problems (still under investigation) and other stuff (a user here told me his Dwarf sometimes add a 10k tone to the main signal and this should help fight it too)
It’s a quite an amount of work for me, and I will now drink my beer in peace. If you want to help me with the plugin door is open!
you can find details about current trained models in my plugin here
like you see in the document I have a model which is called “Edge Of Breakup”
I’m thinking about adding a multiband graph eq to my plugin, something that resembles what Neural DSP is doing on its plugins.
PS: I’ve setup a companion thread for training how to here Training models for amp sims. But we could share a doc here or on Discord group with the “most favourite amps out there” and train the most wanted ones…just an idea btw!
5 Likes
I must have misclicked the “reply” button, cause my comments were about the Epoch amp.
I haven’t tried your creation yet, @madmaxwell but I’d be happy to… if you know of an easy way to run LV2 plugins on Windows 
2 Likes
https://forum.cockos.com/showthread.php?t=250354
never tested it but I would start reading here. For now supporting daw and vsts would be a bit overkill, for the simply reason now users expect a super polished GUI and I don’t have too much interest in this, I prefer audio.
I consider Mod web ui very good in this sense, I can generate a gui in a minute with their sdk.
1 Like
Really nice work @keyth72 ! I compared your EpochAmp to some of my favorite other amps in Amplitube, BiasFX2, ReAmp Studio and Neural DSP. It stacks up pretty well! Mode #2 (“Edge of Breakup” I’m guessing) was the one amp I’d personally use a lot. Just enough breakup, very dynamic, nice EQ. #1 is a nice clean, but it was rather boomy and low level (more than 6dB lower than #2). I could fix it up with a post EQ plugin, but like @Matt said, a tone stack of some sort, even if it was algorithmic instead of profiled would be nice for a future version. Love the look of the UI. One suggestion: because of the shadow effect, the pointers become almost invisible when a knob is at either extreme. The state of the CAB switch is also very difficult to discern. Those are almost forgivable though cuz the louvers for the tube ventilation tells me this is a rockin’ warmth machine. I dig it!
5 Likes
guys I know things are going crazy here, but would you mind move the discussion about the new plugin from @keyth72 (which I surely think it’s great) in a dedicated thread? I would like to keep things here more focused on plugins compatible with Mod products, possibly feedback on my plugin. It seems this Epoch amp is close source, and no release for Dwarf is available atm.
Regarding my plugin, I would like to share some updates. Me and @spunktsch debugged the opt args for the Dwarf toolchain, finally finding a combination that eliminates noise from the output of the plugin. In other words it means I can now publish a release for Dwarf users, and I’m happy to be able to do it given the circumstances. I hope you can provide feedback on the models available, so that we can adjust and decide what we want to train next.
Have a nice we!
11 Likes
just an Update on the live usage of the plugin: worked like a charm and had a good response from friends.
My setup was just the DWARF with the plugin and the mx5 for the fx/ir. Midi switching via ableton. I missed to setup my cam for an audio sample in the room but maybe next time.
Venue was a small room for 60 people - which was packed. Our Sound engineer was glad he only had to dial in one JCM 800. My setup was just straight into the mixer and out to the PA + I got a little more space on stage.


On thing I would do differently the next time is to have a small amp+cab for onstage sound. Notice the sound in the first row was a little lacking.
11 Likes
With 2023 started and 1.13 on the horizon, let’s revive the enthusiasm for the plugin.
For 1.13 we are adding plugin-specific resource folders, let’s start with the Aida DSP Models.
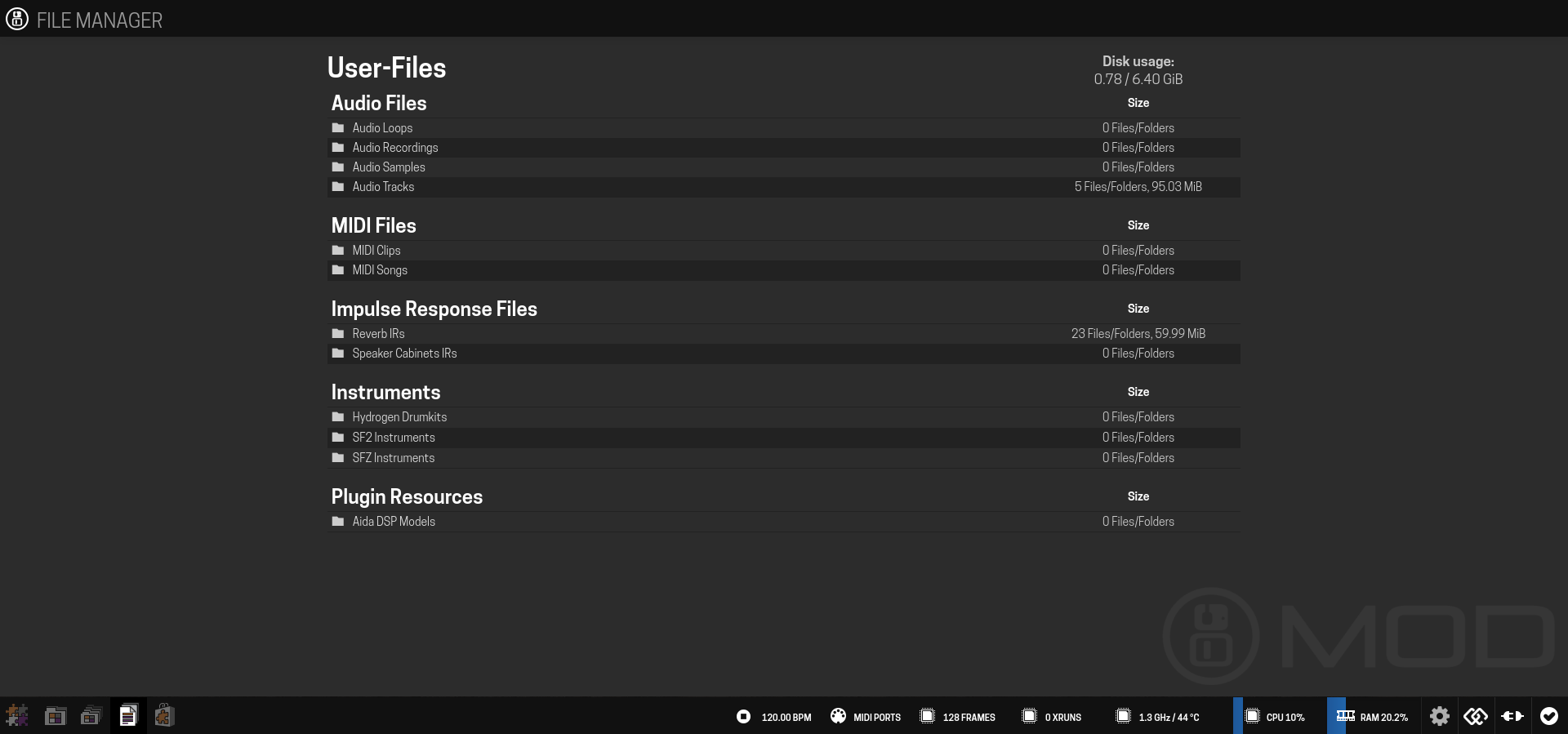
@madmaxwell how do you feel about the naming, is this ok?
we hope to have most things finalized soon enough that we can start publicly start sharing 1.13 builds.
would be earlier than release candidate, so alike beta releases, but good enough to already begin testing plugin builds against the new compiler/toolchain.
18 Likes
by the way, since this is plugin specific I made the file type be plugin specific as well.
So change in the main ttl from:
mod:fileTypes "modelsim" ;
to:
mod:fileTypes "aidadspmodel" ;
will share a 1.13 build with this enabled soon.
5 Likes
Sorry for the late reply busy in the 2023 bring-up. So for the naming I think we should stay with the generic one, modelsim. I mean in my view the author of the model is in the json file together with the other model data. Mine is not even a “custom” format for these neural profiles, since it is just using RTNeural own format. So better to explain a bit. These model files currently part of my rt-neural-generic plugin and in future eventually curated and available on a store for Mod users are the output of a training script that I’ve forked GitHub - MaxPayne86/Automated-GuitarAmpModelling. To be clear it is the same source base as used by GuitarML. The difference is that I have a post-process script that converts the json file from Automated-GuitarAmpModelling into a json file that RTNeural can parse automagically. So that I don’t need to inject weights by hand into the plugin’s sources (like GuitarML does). In turn it also help in tracking regressions between the inference done with pytorch and the inference done by RTNeural. Since convergence problems between different inference engines (I would say libtorch and RTNeural) need to be recognized/tracked. This is my PR on RTNeural to introduce a specific test for this Feature/add test pytorch imported models by MaxPayne86 · Pull Request #79 · jatinchowdhury18/RTNeural · GitHub. That being said, my conversion script can convert also GuitarML models, so in this case it wouldn’t be correct to provide them as Aida DSP’s model files. I won’t do that myself but if anyone want to do it to give these models a shot or if in future other models from other training scripts came out, then would be simply wrong to mark every model as Aida DSP. Hope I’ve explained myself well ![]()
6 Likes
Sorry if this has been asked, but is there any way I can run this on my mod duo x?
Also: this is an idea I’ve had, but do you think it might be possible to train the model with different knob settings, so that you can simulate the knobs too?
The training data would have different knobs as inputs too, basically.
I tried to set this up a while back (with help from @spunktsch) but we learned the Duo X compiler is too old (error was GLIBC_2.27 not found). Not sure if there’s been any change to this as yet.
I don’t understand enough about it to give any helpful answer. Perhaps @falkTX can advise on this?
1 Like
be possible to train the model with different knob settings
Yes it is, just for simplicity we are going with snapshots. The plugin itself with a couple of reverts will support also conditioned models
but we learned the Duo X compiler is too old (error was GLIBC_2.27
Just for you to know, we are now messaging with @falkTX and we’re landing in the store as beta hopefully soon. We’re just fixing bits and test to provide you the best experience. Plugin will run on every device.
15 Likes
you could also try using this implementation…
might be more efficient / more accurate
github > datkinson/neural-amp-modeler
- github > sdatkinson/neural-amp-modeler