Hello, a few months ago I’ve put myself into this crazy neural stuff for audio dsp. Since I was not fully satisfied with NeuralPi plugin (build issues due to JUCE, built-in effects that are not needed on mod platform) I’ve pushed this
Since I have Neural DSP Archetype Plini and I think it sounds amazing, I’ve trained a model over Electric Sunrise: Riff preset without parametrizations (you can’t change gain and volume of the model). This is a very high gain preset for killer riffs.
The result is really promising although cpu consumption for now is really high. By switching to 1024 as buffer size for jackd I was able to hear it and it sounds amazing like the original.
Of course this is a lot subjective, so what I like of the neural approach is that is has ESR measurements embedded into the training workflow, so we can let the numbers talk.
The images below show the response of the trained network against an input which it has never seen (test)

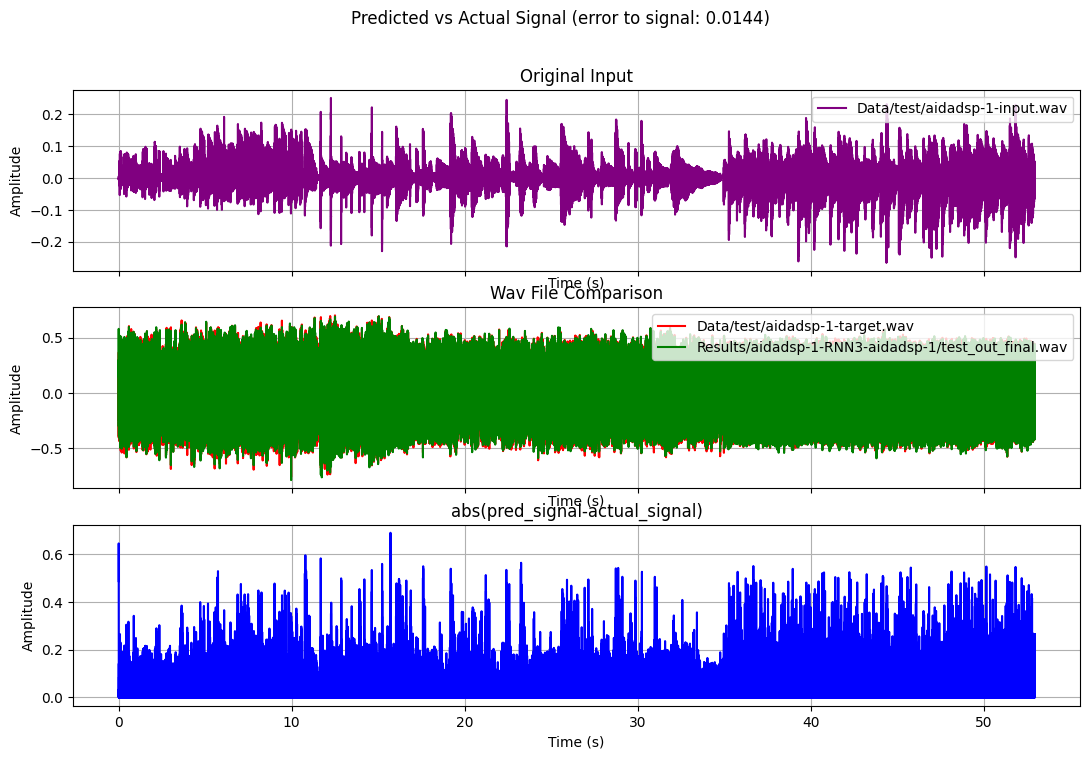
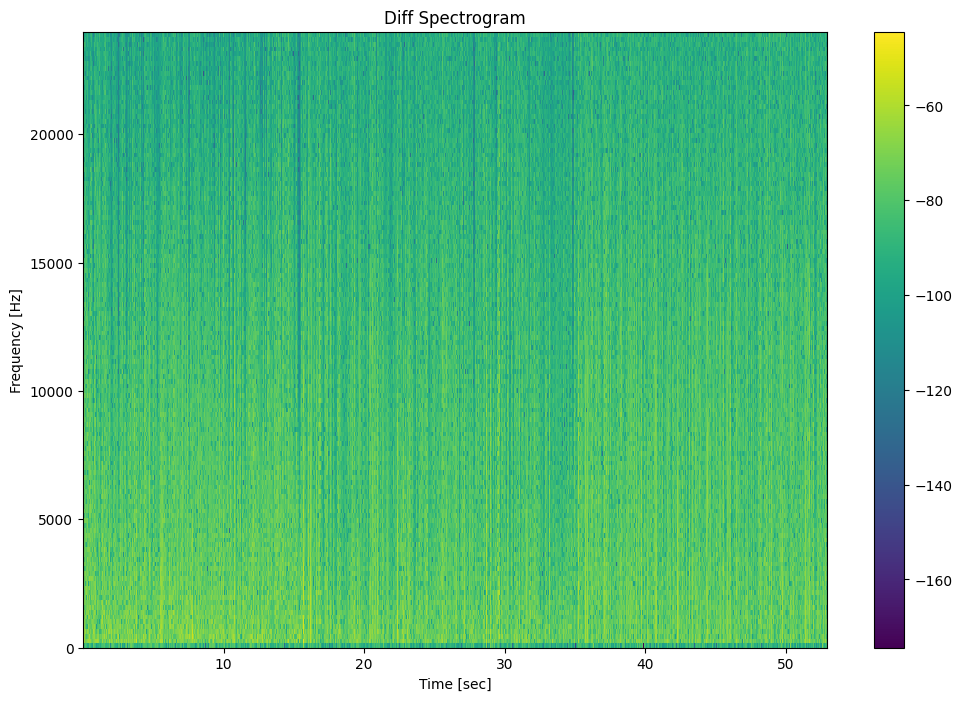
we of course have audio too, see online archive here, go to AI dir and the pick latest training. You can do audio A-B comparison between:
- aidadsp-1-target.wav in Data/test dir which is the original aidadsp-1-input.wav (dry) material rendered through the Neural DSP plugin (I’ve used Reaper DAW on Windows 10)
- in Results dir test_out_final.wav which is the output from the trained neural network
The Dataset used is an original one I’ve put together since I was not fully satisfied with the stock one proposed by original developers.
I’ve also forked Automated-GuitarAmpModelling repo to inject changes needed for using this dataset
I’ve still have a Colab subscription so if you’re interested I can train other models, you just need to record properly the thing you want to model. I can share details of the procedure in a separate thread.
For the lv2 plugin code all the credits go to the original authors @keyth72 @chowdsp and others. I’ve just used LSTM class which let me came with a simple lv2 plugin with 4-5 calls to this class and it’s done. Of course like I said before some development work is needed to shrink cpu usage, not to mention integration with mod-ui filemanager and neural models json files selection, which I would like to add in the future.
OOT: still a little nightmare is mod-sdk, I’ve pulled official docker hub image and also builded latest source in a 18.04 ubuntu container and always getting thumbnail/screenshot deploy error, so @falkTX if everything else is ok I would ask for those two images thanks!
 I’ve switched to models with hidden_size=16 and measured a cpu usage drops by 50%. The hidden_size is specified in the config file of the training, in NeuralPi hidden_size = 20 but in new DarkStar plugin is 16 for reference. In the next days I will focus on cxxflags and ldflags to further improve performance, but the hidden_size seems to play a major role. I will also study for drawbacks in quality when reducing this parameter.
I’ve switched to models with hidden_size=16 and measured a cpu usage drops by 50%. The hidden_size is specified in the config file of the training, in NeuralPi hidden_size = 20 but in new DarkStar plugin is 16 for reference. In the next days I will focus on cxxflags and ldflags to further improve performance, but the hidden_size seems to play a major role. I will also study for drawbacks in quality when reducing this parameter.