Looking to improve our amp modeling techniques, we conducted experiments modeling the Peavy Bandit 112 Silver Stripe.
Here I share with you the variables of the experimetation, the results, and some interpretations of the results in the end. We focus particularly on the data capture setup.
If you’re just interested in good sounding models of the amp, this is for you.
In the process of capturing the sound of the AMP, we tested 2 “reamping” setups:
-
Using a DI:
This setup allowed us to record both the amp-head signal, and the cabinet sound (using a mic) at the same time. -
Using a Loadbox:
Here we only capture the sound of the amp-head.
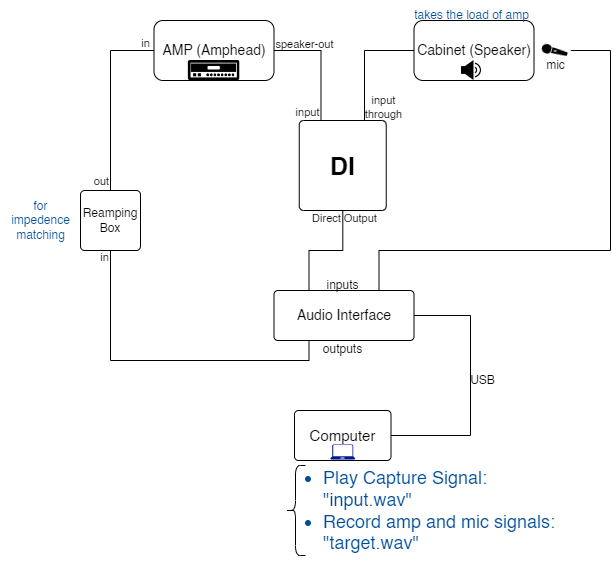
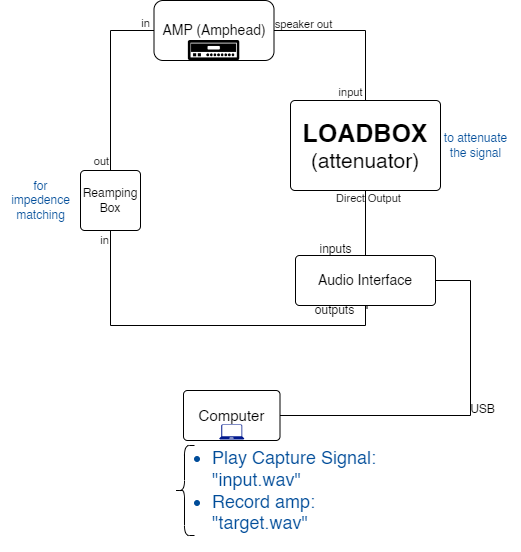
We captured the sound on 4 different amp configurations:
- Clean
- Clean2
- Crunchy
- Gainy
In the training, we used 6 different model architectures
- Lightest (LSTM-8) with skip_connection = ON
- Light (LSTM-12) with skip_connection = ON
- Standard (LSTM-16) with skip_connection = ON
- Heavy (LSTM-20) with skip_connection = ON
- Light (LSTM-12) with skip_connection = OFF
- Standard (LSTM-16) with skip_connection = OFF
RESULTS:
Here’s a directory containing all (60) the resulting models:
Here’s an excel sheet summarizing the training results of those 60 models (ESR, and final training epochs):
Interpretations:
-
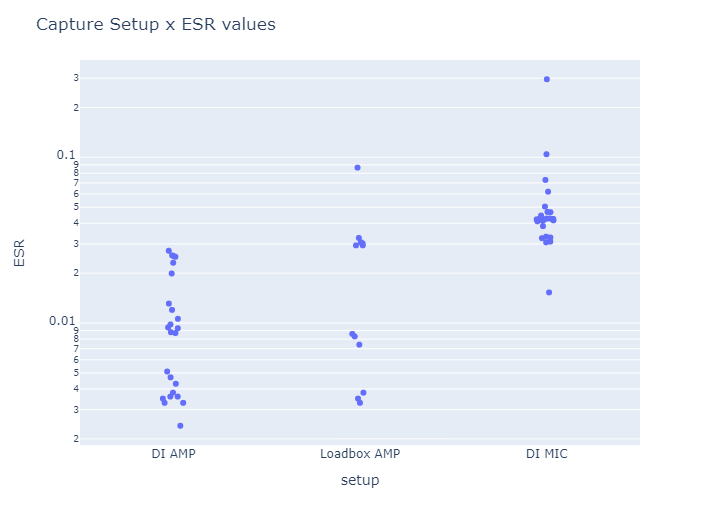
Comparing setups:
→ This shows that training models on the amp-head signal alone, rather than the sound from the cab, can lead to greater accuracy.
This is likely due to the simpler signal chain of amp-head alone, compared to the more complex [amp-head → cab] signal chain.
→ After comparing the results of the two setups, we found that setup1, which uses the DI, was more effective at capturing the sound of the amp-head. When we trained models on the amp-head signal using setup1, we noticed that the resulting models are more accurate and (arguably) sounded better to us compared to the models trained using setup2. -
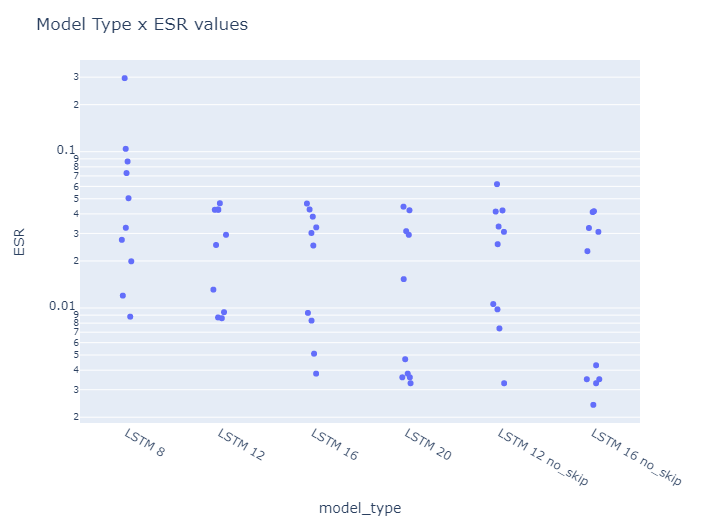
Comparing model types:
→ Disabling skip_connection can improve model accuracy. However, this can not be generalized yet, as we have to experiment with more tones and amps.
→ As expected, the bigger the model size, the more accurate they are. -
Comparing different amp tones:
→ I cannot derive any conclusions from this. The amp tone doesn’t seem to have an effect on the accuracy of the models.
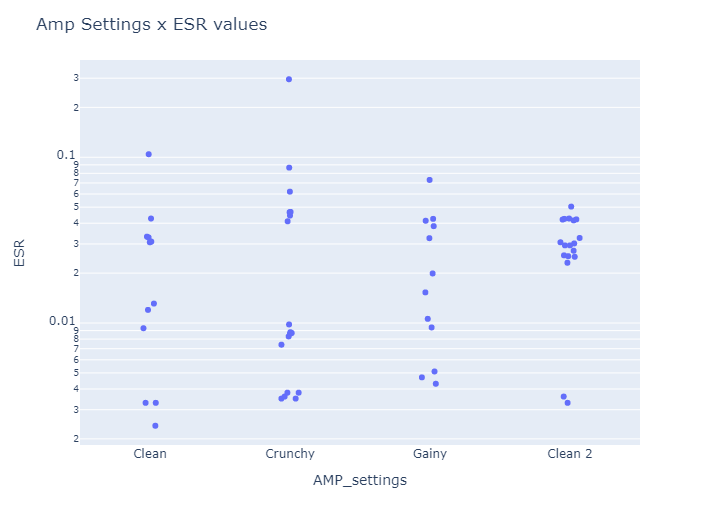
These intnerpretations may be only valid to this Peavy Bandit amp. In the near future we’re looking to capture more AMPs and pedals!
Please feel free to give feedback on our experiment and how we interpreted the results. If you have any experience with modelling yourself, this can also add more insights!
This is also missing feedback on how the trained models sound, let me know if you tried a bunch of them!
