Hmm. Your files processed fine for me.
Current model: deerinkstudios-bogner-red_LSTM-16
ESR: 0.028407106176018715
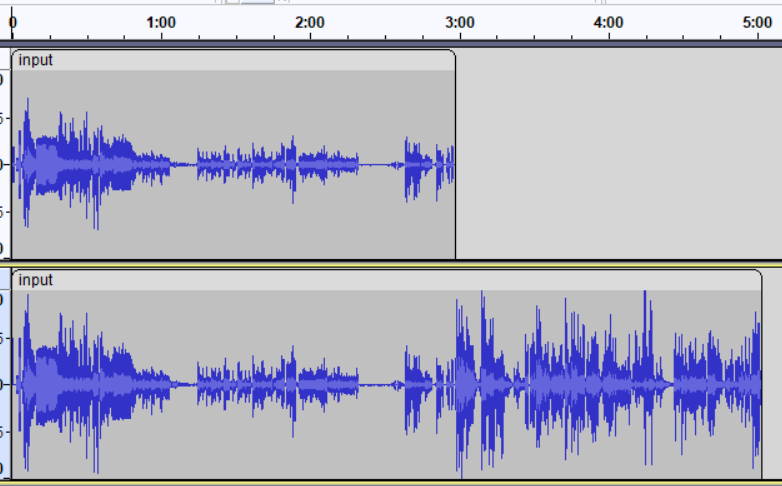
Interesting is that your input.wav differs from the one I’ve downloaded by link from the AIDA-X Model Trainer.ipynb provided by MOD modelling tutorial Your input.wav is two minutes shorter, missing some real guitar licks in addition to the first 3 minutes of creepy noises. Why? ![]()
However, cutting my own input and target to the same size does not make any difference, unfortunately.