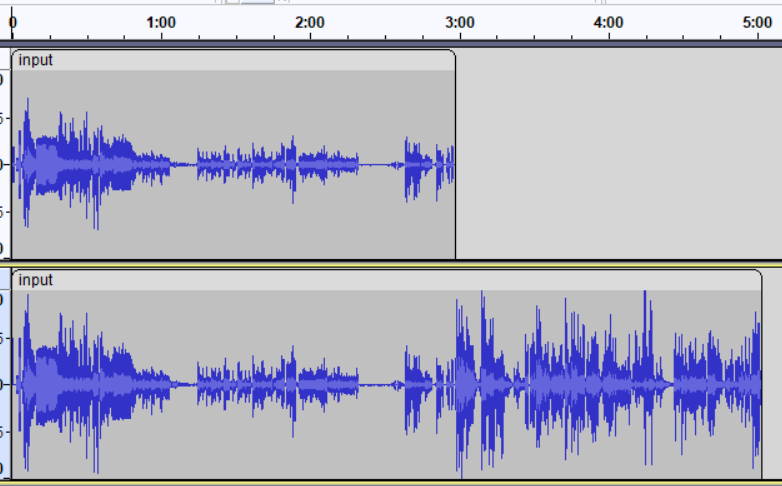
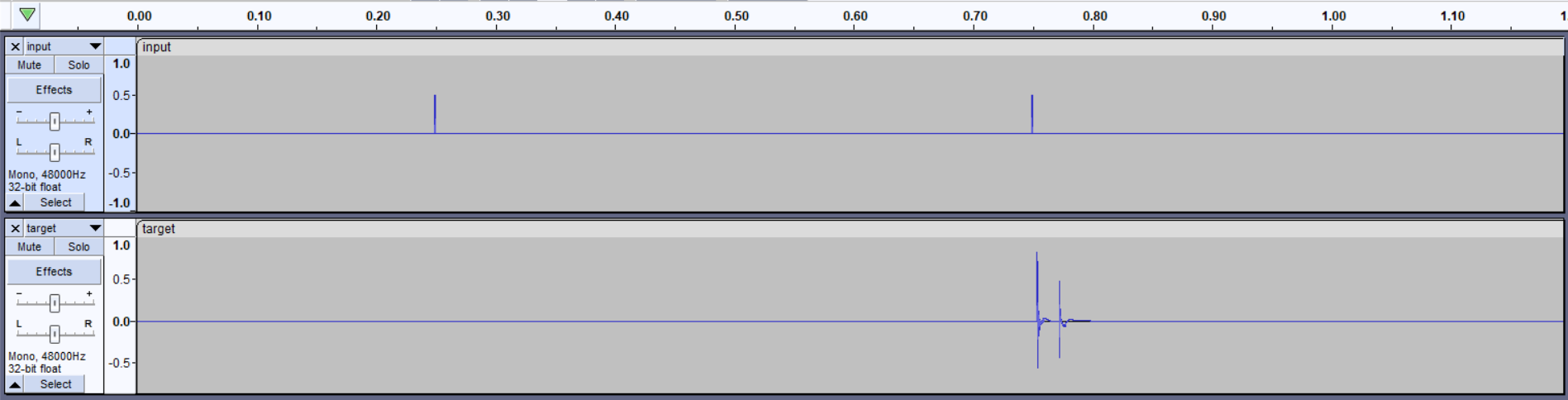
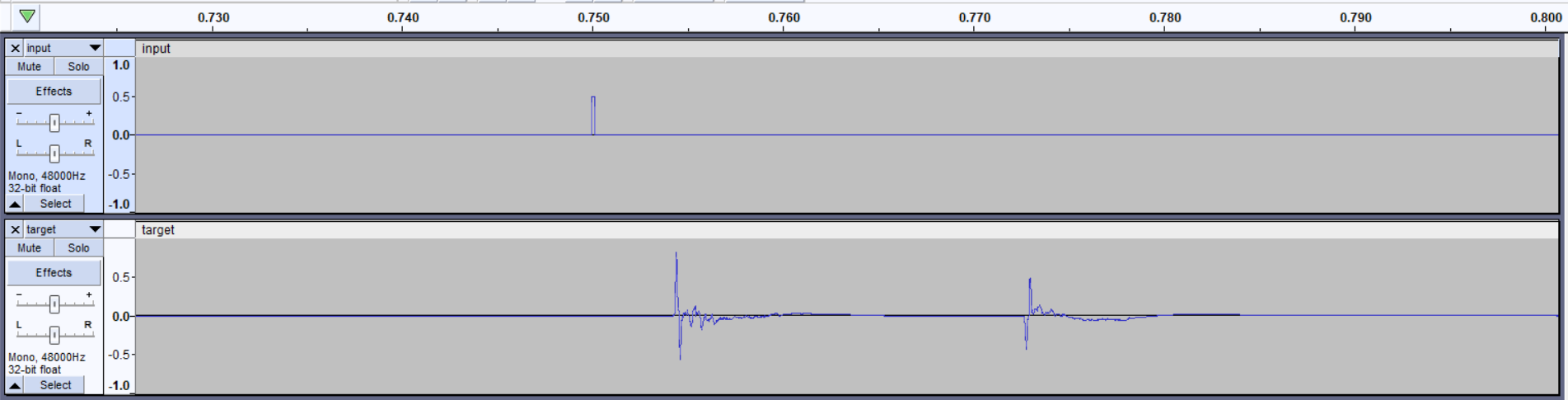
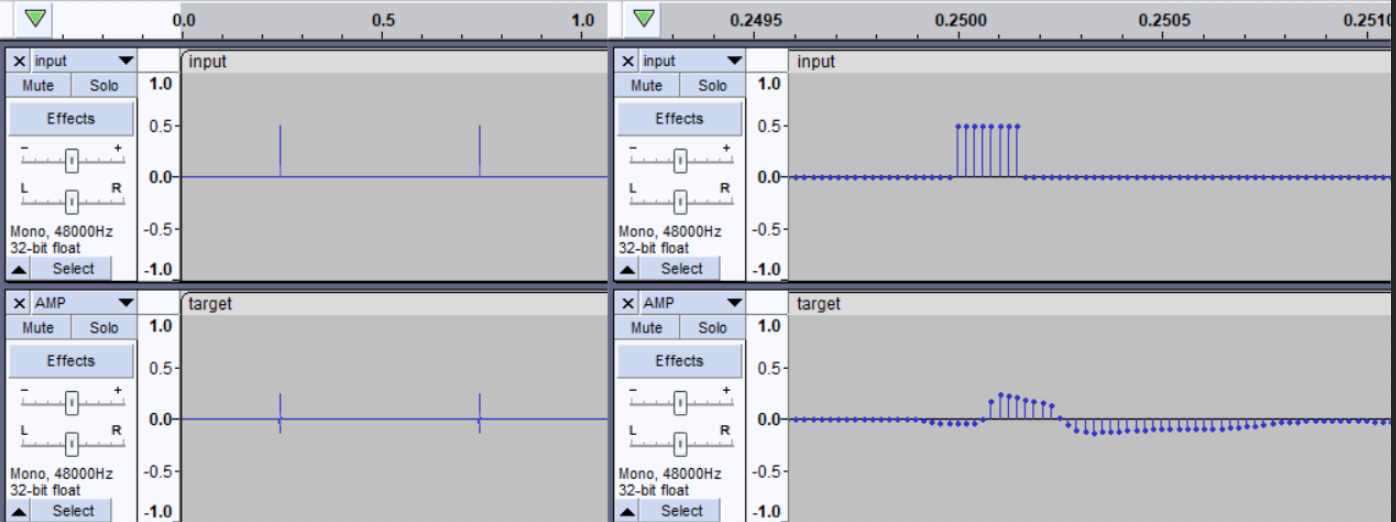
Hi guys, I am bumping into this when training.
I am not completely sure what this message means, but looks to me like training fails prematurely, being unable to achieve any useful results.
Also I do not know what ESR is, but to my guess that’s probably some kind of deviation metric, that can indicate quality of the model, and for the working json’s I’ve seen this esr value is much closer to zero, and mine is almost 1.
Also result, “predicted” sound does not resemble “target” even far.
Any ideas what I could make wrong?
---
device = MOD-DWARF
file_name = drive
unit_type = LSTM
size = 8
skip_connection = 1
35%|██████████████▎ | 105/300 [04:08<07:17, 2.24s/it ]**validation patience limit reached at epoch 106**
35%|██████████████▎ | 105/300 [04:11<07:47, 2.40s/it]
done training
testing the final model
testing the best model
finished training: drive_LSTM-8
Training done!
ESR after training: 0.9969175457954407
P.S. I am running learning via Colab connected to the “local environment”, where local environment is on my windows laptop with jupyter docker container in WSL2, based on the aidadsp/pytorch image.
It seems to be an exotic setup, so I should mention this, in case if I’ve shot my own leg with going this way.
FROM aidadsp/pytorch
USER root
RUN apt update && \
apt -y install git
RUN mkdir /content && \
chown aidadsp /content
USER aidadsp
RUN pip install jupyter_http_over_ws && \
jupyter serverextension enable --py jupyter_http_over_ws && \
pip install librosa plotly
USER aidadsp
#instead of the goole drive input
RUN mkdir /content/drive
RUN mkdir /content/drive/input
WORKDIR /content
ENTRYPOINT ["jupyter", "notebook", "--ip='*'", "--port=8888", "--allow-root", "--NotebookApp.allow_origin='https://colab.research.google.com'", "--NotebookApp.port_retries=0"]