Taking a look at the input files that you provided @ignis32, I can notice 2 issues:
First thing you can see in the beginning of the audio files, that for the first pop in the input file there’s no corresponding pop in the target file, and for the second pop in the input file there’s somehow 2 pops in the target file. Now I don’t really understand how that happened, but similar things seem to be happening during the rest of the files as well.
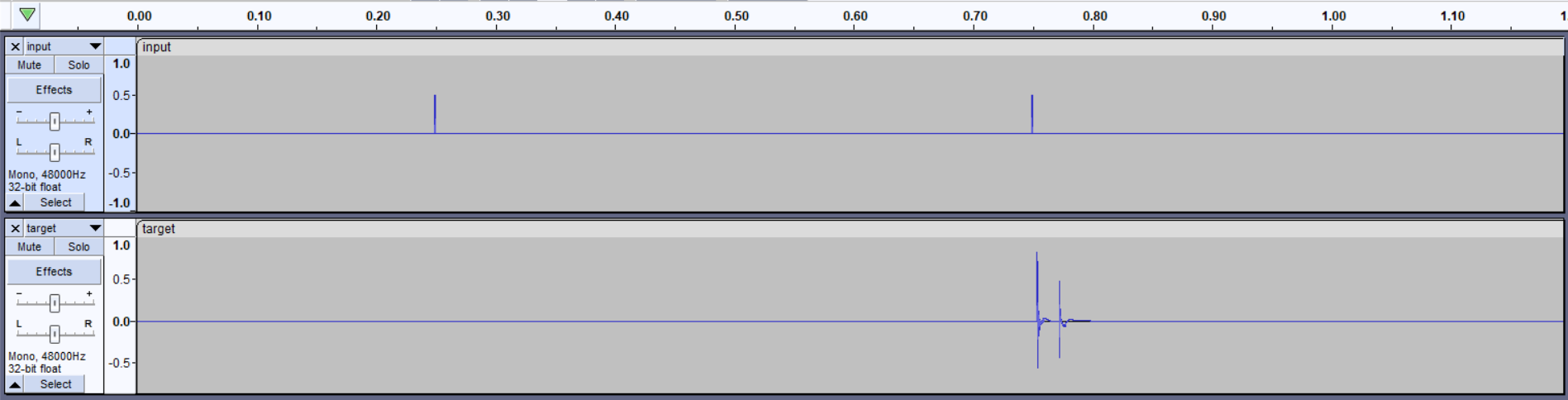
Second: taking a closer look at the second pop and how the target reacts to that, you can see that there’s a latency of at least 5ms between the pop in the input signal and the target signal (assuming that the 1st pop in the target corresponds to the 2nd pop in the input).
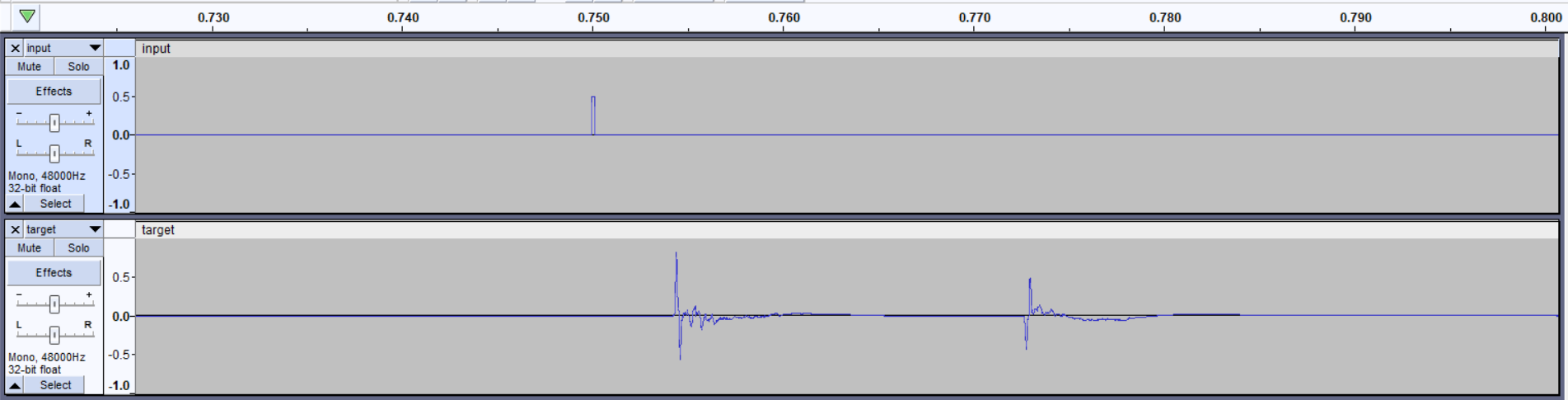
These issues defintely explain the inability of the model to converge to a good solution. Issue 1 means that somehow there’s no clear operation that gets you from input to target. Issue 2 means that the model would have to generate the target sound with a latency of at least 5ms (which is not only difficult for the model, but also not appreciated when playing in realtime haha)
Now these issues may have happened during the reamping process or if you did some quick processing after the reamping. My advice is just to pay more attention to that, data is pretty crucial when it comes to AI in general and our case specifically.
For comparison, here’s how other valid reamping files can look like in terms of response and response time.
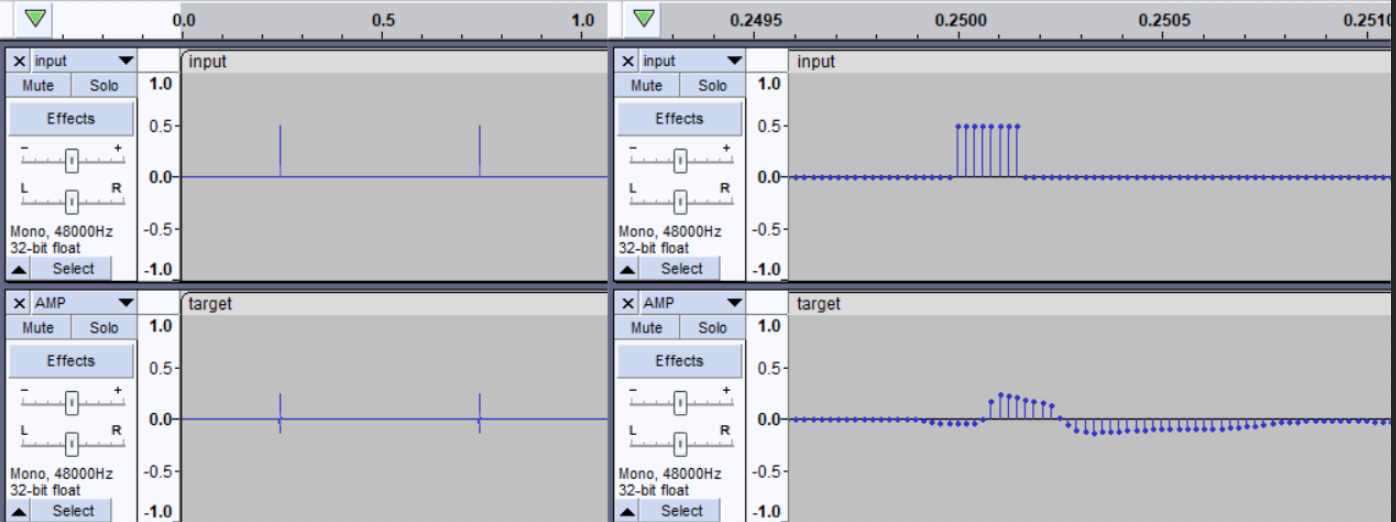
Hope this helps, let us know if you manage to fix it!