I don’t think that is a negative thing, doesn’t that mean the algorithm recognizes that it isn’t learning anything new and it doesn’t need the time to know what it’s about?
can’t really answer the second question since I always select a new folder on my drive for every new model so I start from that step again
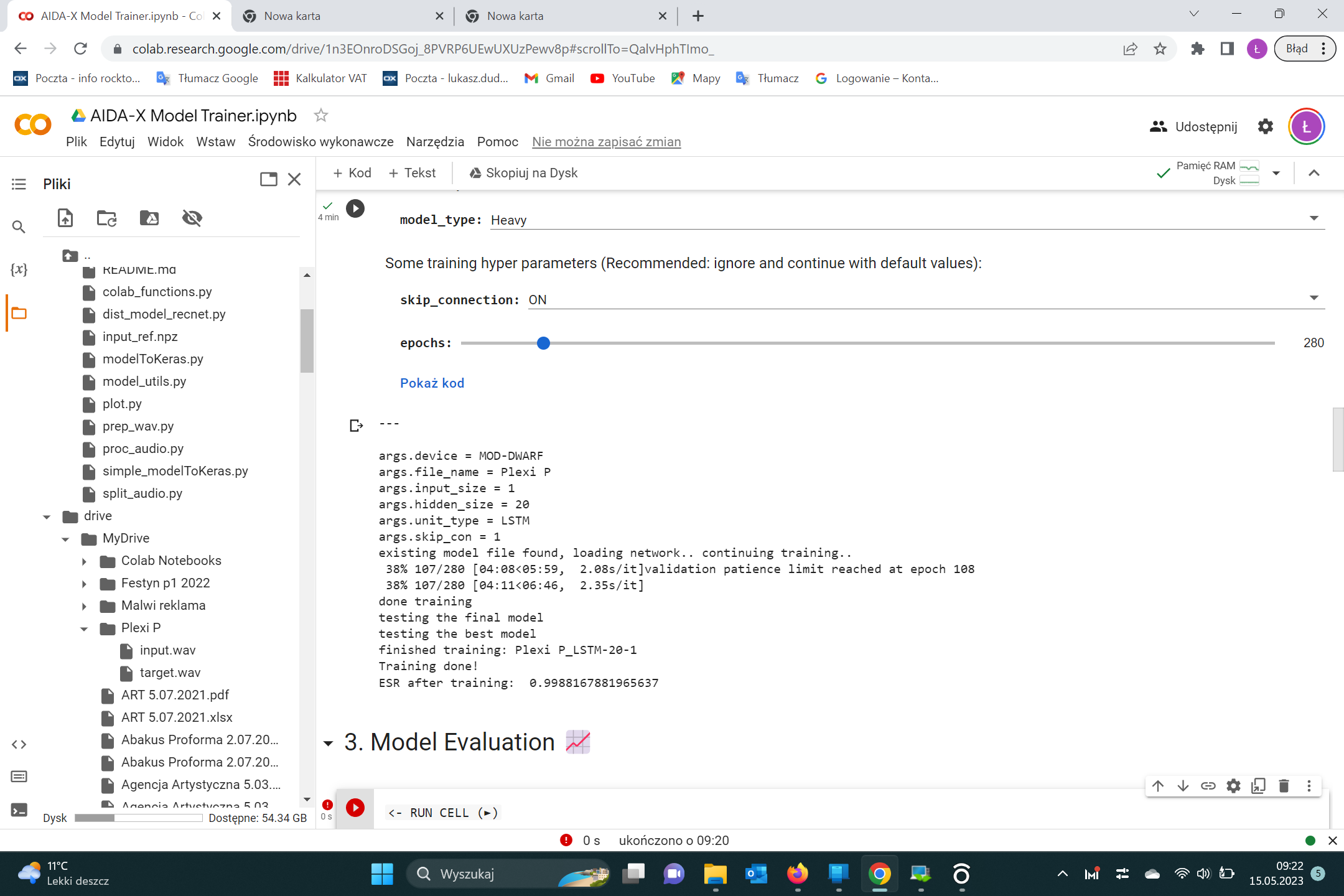
the first thing is totally normal. As @LievenDV said it stops when the model is already the best version.
(should be a easier to understand prompt on our side of the training)
The second thing is as like you said: it starts the training with the previous results.
You just have to delete the folder of the models in the Results folder.
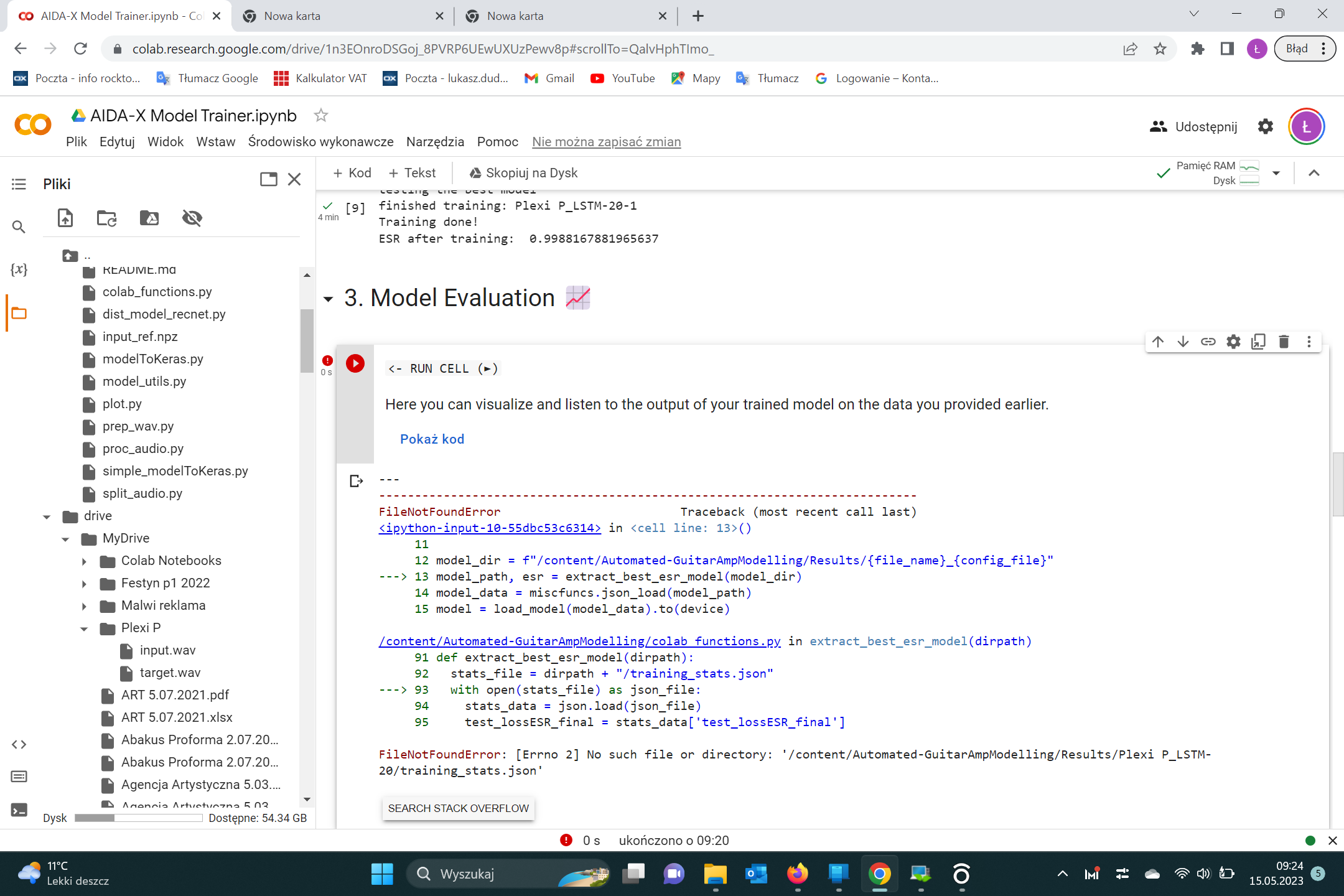
So, I made a few attempts at making models, but in the end, my ESR ended up somewhere between 1.000xxxx and 0.9xxxx, and from what I recall, that’s bad. Also, the best one (0.9xxxx) ended up completely silent. I think my issue was getting the input and target audio lined up perfectly. After recording, I use audacity to line up the 2 files. I line up the 2 clicks at the beginning, but by the end of the file, there appears to be some drift. So, to combat this, I decided to record both Dwarf outputs to a single stereo track. Output 1 going through the amp, then the audio interface, output 2 going straight to the audio interface. Finally, in Audacity, I split the stereo track into 2 mono tracks and save one as target.wav and one as input.wav. This solved the problem and my resulting ESR ended up at 0.0012241610093042254, which is a lot better, and sounds pretty decent. Just thought I’d post this here for anyone else facing similar issues.
Should we suggest that people delete their results folder after creating a model?
(as a cleanup courtesy but also to avoid influencing their results if they do a new attempt on a model?)
I’ve been really interested in doing some modelling of some pedals, just had to borrow a reamp box.
It’s only just dawned on me that I could just use a DI before the pedal and a DI after. I have a Jad Freer Capo which is already configured with a clean DI of the bass and a DI with my preamps and drives
Serves me right for not reading the guide! I’d assumed there would be a some kind of special input signal that would be used rather than just a guitar signal.
Is there a benefit to using raw guitar as an input for training rather than a specialised signal that sweeps through frequencies and volume etc?
Not everyone has equipment ready for streaming an audio file into their hardware
A full volume and frequency sweep might produce significantly more weights/parameters to store in the model and require more CPU to run, even if you’re only using a fraction of spectrum captured in your playing.
A volume and freq sweep doesn’t capture many of the techniques that guitar players use to alter their tone and dynamics like bends, slides, mutes, polyphony / chords, attack / picking style. These can vary greatly from player to player. If your gig is wailing on low power chords, you probably don’t need the model “cluttered” with response data for bending the high E string.
the dataset does not influence how many weights are saved and how much CPU it consumes. That is consistent with the network/configs you choose.
absolutly correct. You could even go that far and have a model of you bass sound for every specific song/type of music. Record a dataset and train it with that.
Super useful, so the goal should be to create a personalised dataset based on your playing and requirements etc.
For context I’m planning on experimenting with modelling 3 pedals, possibly combinations of them that I commonly use so that I can run it with a single AIDA-X module.
I was trying to get my head around how I could best get a model that would work for both but tbh sounds like I’ll probably get better results having specific guitar and bass versions.
Hopefully will get chance to play tomorrow. Got a pretty good idea now of what my first approaches will be now, thank you!