I don’t think that it was possible to directly convert them. But if we have the clean audio and the output target, it could be possible by training Aida DSP model. Although, I saw that people share the model trained instead of original material. ![]()
1 Like
you have to dig a little but some release the output with the models. Dropbox - Parameters - Simplify your life
1 Like
So much cool stuff happening in the this / the MOD Universe these days! ![]()
2 Likes
When I sad output, I was referring to original amp output audio instead of the error image ![]()
I thought more and conclude that with the NAM model, it’s possible to record a new clean sound and a new output sound (sound processed by NAM model). Them, with these two files, training a new Aida DSP model. So, Aida DSP will try to learn the NAM model instead of the original amp.
In other words, Aida DSP will be an emulation of an emulation of an amp/effect. There isn’t the “perfect world” but if the error was minimum, would works.
Remembering that training step is something that could be expensive. Then there isn’t expected that exists a website when you put a NAM file and receive an Aida DSP in seconds.
1 Like
thats what the output.wav is. ![]()
thats also possible. The training for aida is nearly the same as for NAM. A little easier to setup but in the end it could be a combination for both platforms. You just have two files at the end. One for NAM one for aida.
2 Likes
the simpliest way to “port” existing NAM models to Aida is to use the provided input.wav/output.wav files and re-train using our training script. Which is not dissimilar to the training script used by NAM, since in the end we both use pytorch and Jupyter notebook to drive the training process. We went a bit further maybe since we now provide the possibility to do training in a docker container, which is really convenient imho. We will provide instructions on “how to retrain NAM models for Aida DSP”. The quality however, at least from “numbers” perspective, would probably decrease when re-training with the network used with Aida DSP. The problem is that if the NAM dataset works really well with their Wavenet network, the same dataset with another network type (In Aida we use RNNs) could provide different results. Infact, we use a completely different dataset to train our models.
the harder way would need probably to discuss things with original NAM developers. But the basic idea would be to “merge” the training scripts. And more important to let them export the model in a format that is compatible with RTNeural. As developers, we don’t want to have multiple/custom inference engines implemented in every neural plugin. We want to converge toward a single and flexible inference engine with a focus on rt-audio (which is, imho, RTNeural) and possibly have everybody to contribute to the quality of this core piece of every neural plugin. Or at least this is my proposal. However even considering a script to convert NAM model to Aida DSP or whatever, the main problem remains that NAM models are Wavenet models which are indeed too heavy for embedded systems. This is a known problem also for NAM developers, but currently they’re focusing more on VST kind of users.
6 Likes
is there any sound examples of models trained by the neural plugin that is going to be in the MOD?
there are some videos in the works.
but the idea is to allow people outside of MOD to use these models too, that should become possible very, very soon by means of a more generic CLAP/VST2/VST3 plugin built for desktop.
just a few more details and some early tests can begin.
let me know if interested.
7 Likes
Looks awesome. Would it be a Paid or Free plug in?
2 Likes
the loader is fully opensource and free, both for the version in MOD and the desktop plugin too.
4 Likes
I’m not so “nerd” and my english is not so good, sorry, but I tried NAM these days and I think is awesome, so if you record a video tutorial for installation on Dwarf (I checked on beta plugins but can’t find) I will be happy to test it and give some opinions
1 Like
The NAM plugin does not work on the Dwarf, and neither on the Duo X.
It is too heavy (as in, uses too much CPU), which is one of the reasons to go with an alternative for MOD.
We hope to have both desktop and MOD versions of the AidaDSP plugin ready for testing very soon, alongside some documentation on how to generate the model files. Ideally the same process generates models using “old style” NAM with WaveNet, and the new RTNeural based one (that runs much faster).
And when I say “soon” I mean still this week.
8 Likes
I am really hyped for this. And the documentation to generate the model files are very welcome. Would it be cool to post also a video step by step explaining how to create the models.
1 Like
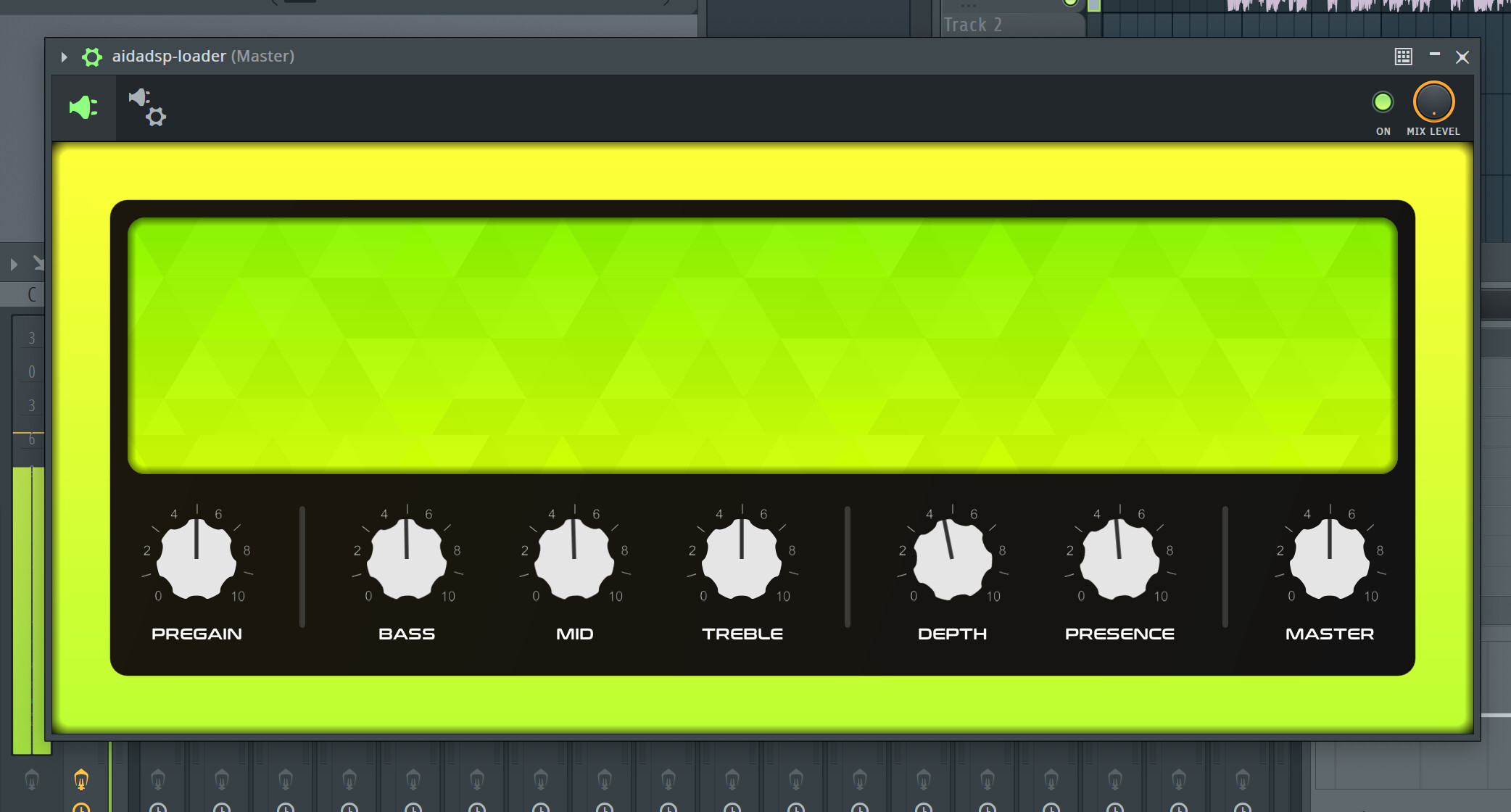
Is this an opportunity to create and pitch ideas for a small, readable GUI?
The venom green hasa nice flair but the sheer ‘useful’ size and reability of controls etc could be a better mix of ergonomics and design.
More so; perhaps @Kim and I can join forces to come up with a mockup? ![]()
3 Likes
thanks @LievenDV . UI is pretty much taking care of. The image is missing a lot of branding and stuff so not the full UI.
But I’m always open for suggestions and I taken a lot of hints from past threads. ![]()
5 Likes
cool, feel free to run it past “The Committee” any time ![]()
I’m kinda hyped as well; this could be another strong USP for the MOD devices and Universe.
3 Likes
yeah, I just wanted to share an early pic showing the plugin loaded on a DAW.
added in a few more elements now, slowly looking a bit like the proper deal…

need to dedicate a part of the GUI to handle the json module loader, then also a cabinet IR thing too because it is so common (and to be more alike NAM drop-in replacement, it should have it too)
I think we can move the logo to the left a bit, and add these details on top of the “head” background.
10 Likes
Is there a reason why there are lots of different knobs for the plug in, like the EQs and pregain, etc.? I was assuming that the neural net itself is only a snapshot, with the knob settings not given as input. I guess it’s just for convenience?
Without such controls, those profiles would be too limited as “one trick ponies” and you have to try to tweak it out after its master volume.
I do wonder how presence (and its opposite “depth”) will work on those. Is it a certain EQ range that gets cut/boost? Is it the same Freq range as the depth and presence on the Veja Mutant?
we’re preparing doc for this with everything explained. Presence is an high-shelf, depth is a parametric boosting low end.
2 Likes